Publications
Research publications from our group.
Test-time Sparsity for Extreme Fast Action Diffusion
Kangye Ji, Yuan Meng, Jianbo Zhou, Ye Li, Chen Tang, Zhi Wang
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026
A test-time sparsity method for accelerating action diffusion models to achieve extreme fast inference.
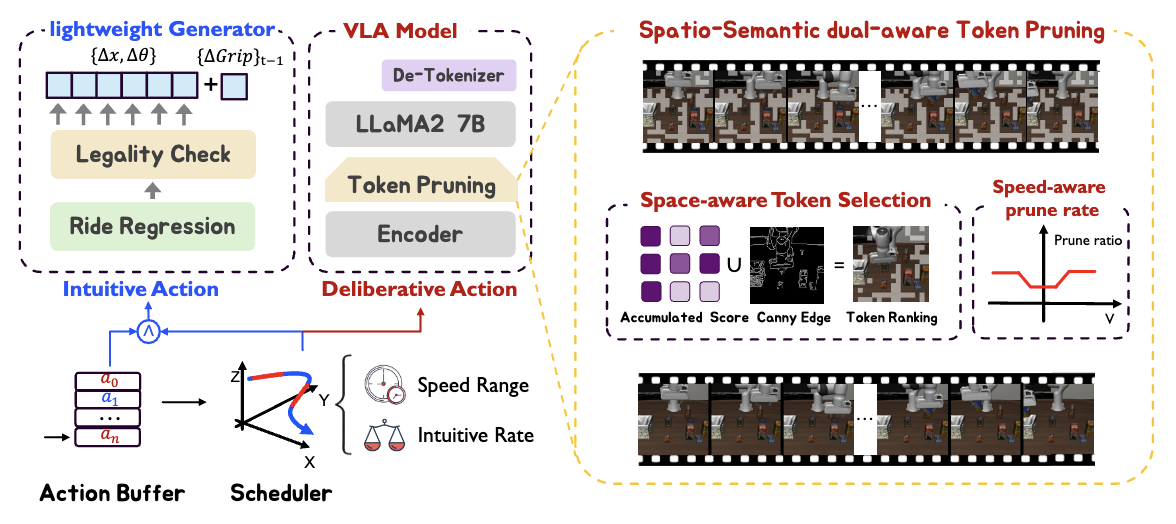
SP-VLA: A Joint Model Scheduling and Token Pruning Approach for VLA Model Acceleration
Ye Li, Yuan Meng, Zewen Sun, Kangye Ji, Chen Tang, Jiajun Fan, Xinzhu Ma, Shutao Xia, Zhi Wang, Wenwu Zhu
International Conference on Learning Representations (ICLR) 2026
A joint model scheduling and token pruning approach for accelerating Vision-Language-Action models.
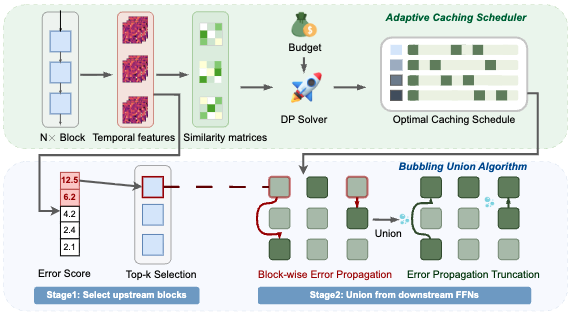
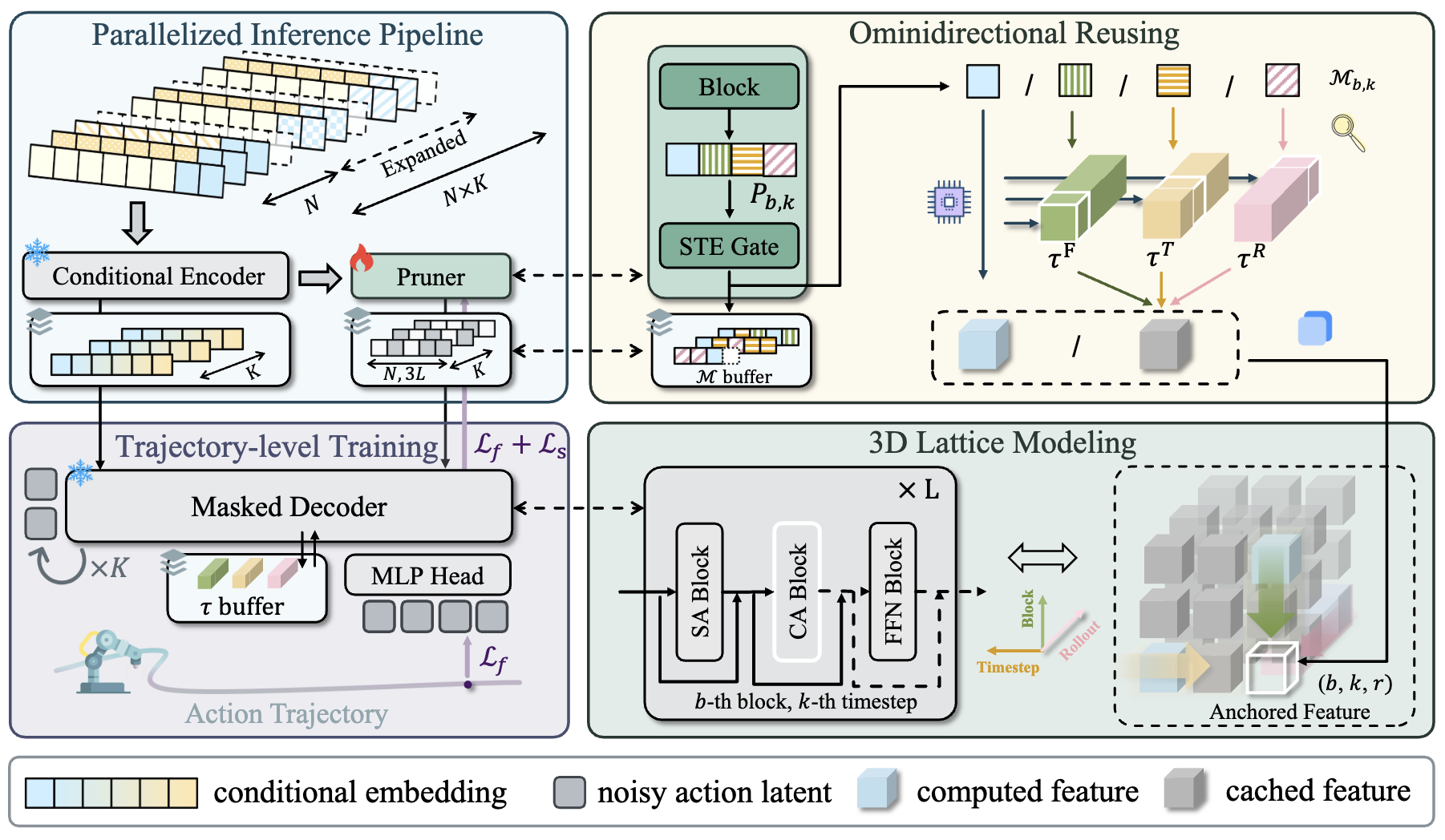
Block-wise Adaptive Caching for Accelerating Diffusion Policy
Kangye Ji, Yuan Meng, Hanyun Cui, Ye Li, Jianbo Zhou, Shengjia Hua, Lei Chen, Zhi Wang
International Conference on Learning Representations (ICLR) 2026
A block-wise adaptive caching approach for accelerating diffusion policy inference.
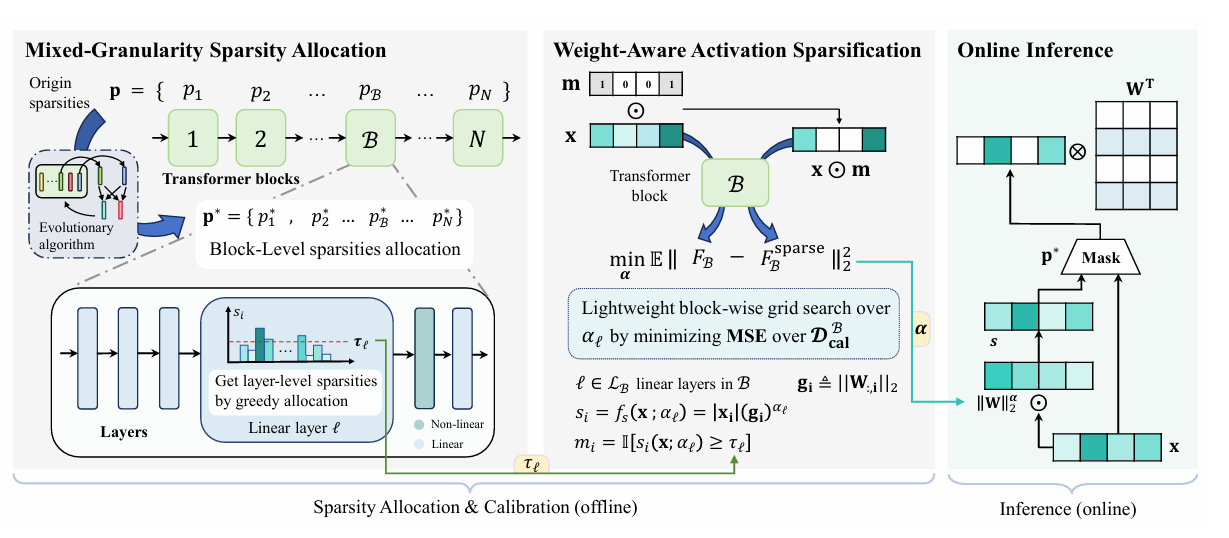
WiSparse: Boosting LLM Inference Efficiency with Weight-Aware Mixed Activation Sparsity
Lei Chen, Yuan Meng, Xiaoyu Zhan, Zhi Wang, Wenwu Zhu
arXiv preprint 2026
Weight-aware mixed-granularity activation sparsity for training-free LLM acceleration with adaptive sparsity allocation across blocks.
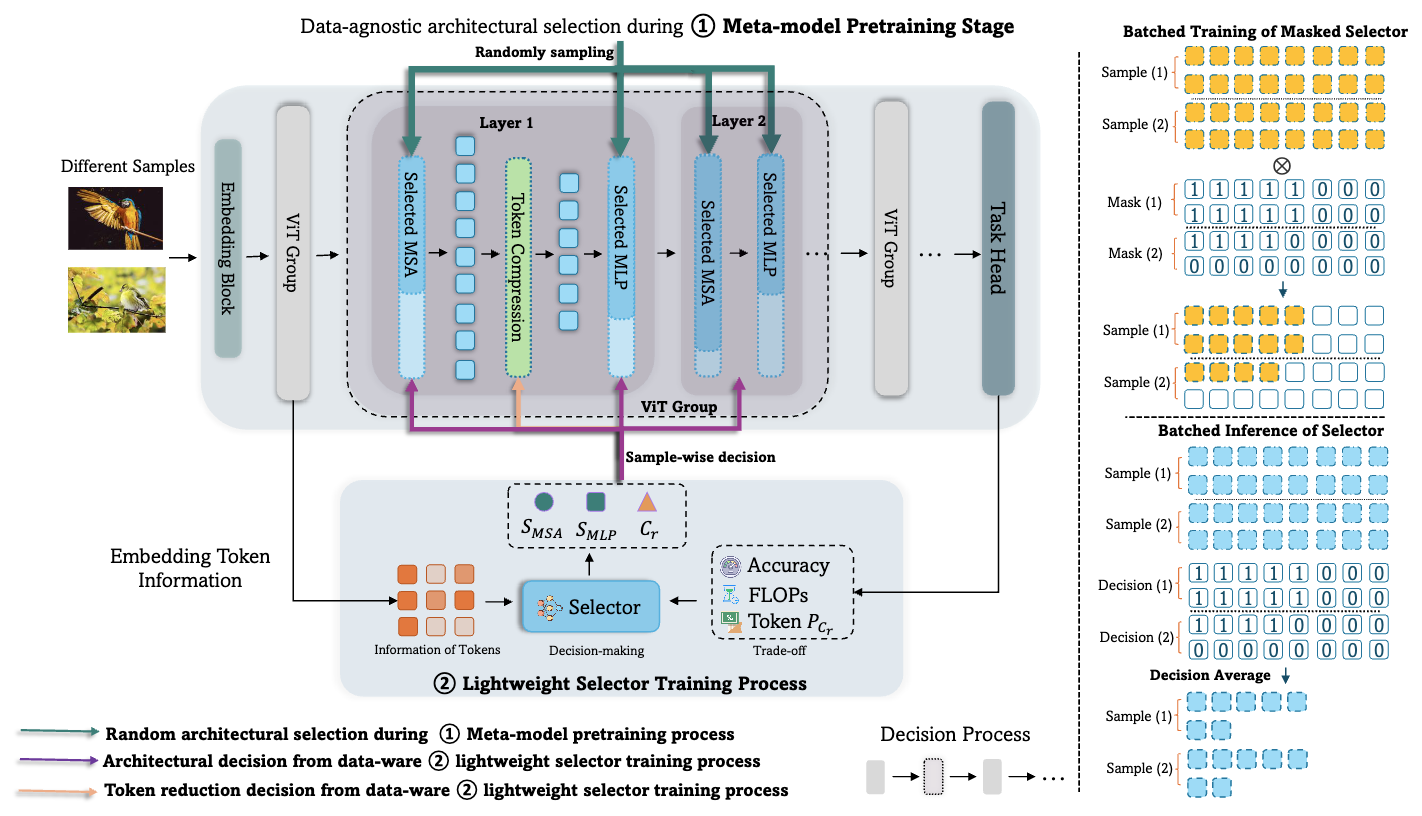
Prance: Joint token-optimization and structural channel-pruning for adaptive vit inference
Ye Li, Chen Tang, Yuan Meng, Jiajun Fan, Zenghao Chai, Xinzhu Ma, Zhi Wang, Wenwu Zhu
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2025
A joint token-optimization and structural channel-pruning approach for adaptive vit inference.
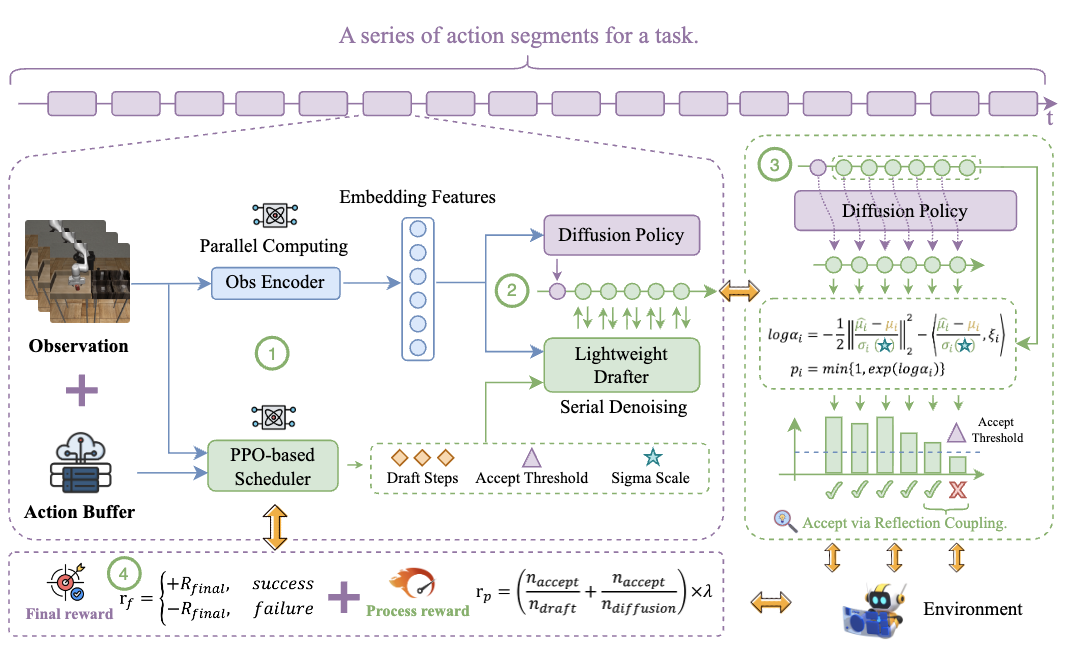
TS-DP: Reinforcement Speculative Decoding For Temporal Adaptive Diffusion Policy Acceleration
Ye Li, Jiahe Feng, Yuan Meng, Kangye Ji, Chen Tang, Xinwan Wen, Shutao Xia, Zhi Wang, Wenwu Zhu
arXiv preprint 2025
A reinforcement speculative decoding method for temporal adaptive diffusion policy acceleration.
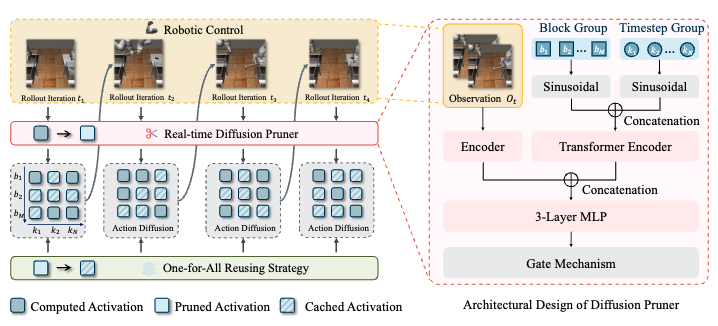
Sparse ActionGen: Accelerating Diffusion Policy with Real-time Pruning
Kangye Ji, Yuan Meng, Jianbo Zhou, Ye Li, Hanyun Cui, Zhi Wang
arXiv preprint 2025
A real-time pruning method for accelerating diffusion policy in embodied AI.
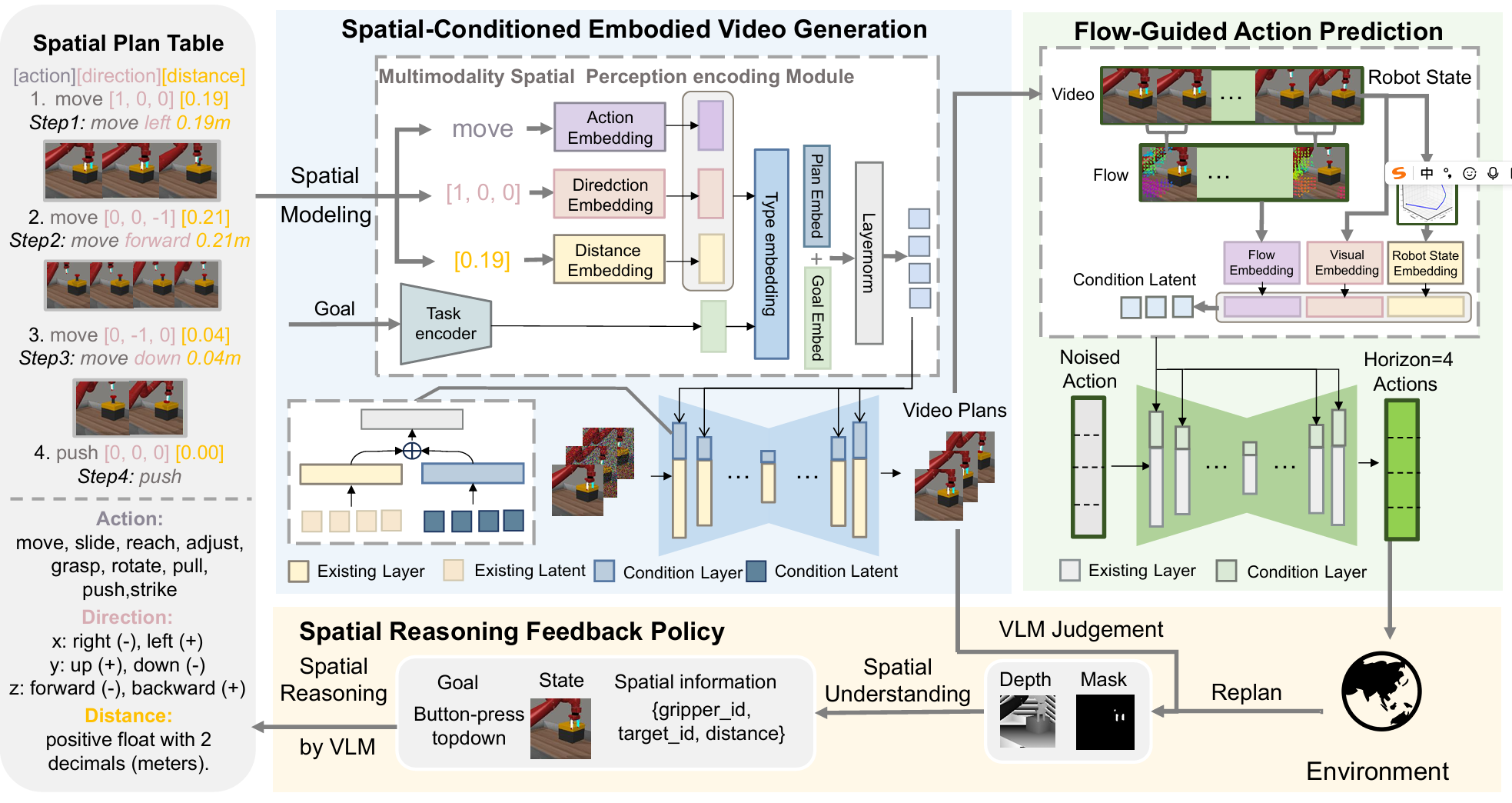
Spatial Policy: Guiding Visuomotor Robotic Manipulation with Spatial-Aware Modeling and Reasoning
Yijun Liu, Yuwei Liu, Yuan Meng, Jieheng Zhang, Yuwei Zhou, Ye Li, Jiacheng Jiang, Kangye Ji, Shijia Ge, Zhi Wang, Wenwu Zhu
arXiv preprint 2025
A unified spatial-aware visuomotor robotic manipulation framework via explicit spatial modeling and reasoning, achieving over 33% improvement on Meta-World and over 25% improvement on iTHOR.

Quantization Meets OOD: Generalizable Quantization-aware Training from a Flatness Perspective
Jiacheng Jiang, Yuan Meng, Chen Tang, Han Yu, Qun Li, Zhi Wang, Wenwu Zhu
ACM International Conference on Multimedia (ACM MM) 2025
A flatness-oriented QAT method (FQAT) to improve out-of-distribution generalization; introduces layer-wise freezing to mitigate gradient conflicts between QAT and flatness objectives.
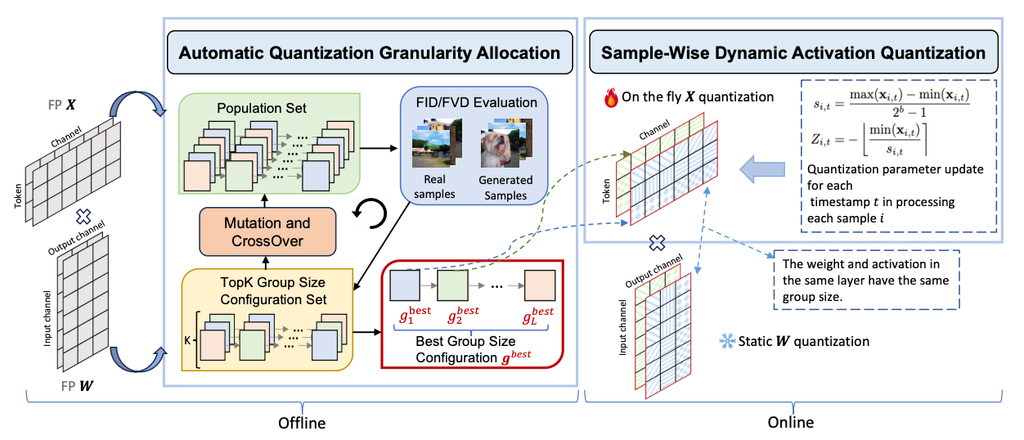
Q-DiT: Accurate Post-Training Quantization for Diffusion Transformers
Lei Chen, Yuan Meng, Chen Tang, Xinzhu Ma, Jingyan Jiang, Xin Wang, Zhi Wang, Wenwu Zhu
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025
Addresses large channel/dimension variance and step-dependent activation shifts in DiT quantization; proposes automatic granularity assignment and dynamic quantization. Achieves lossless W6A8 and about 20% lower FID than prior SOTA.
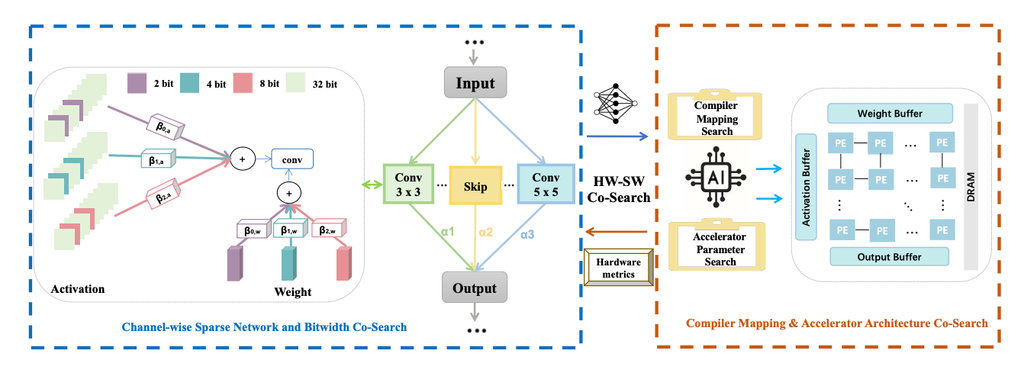
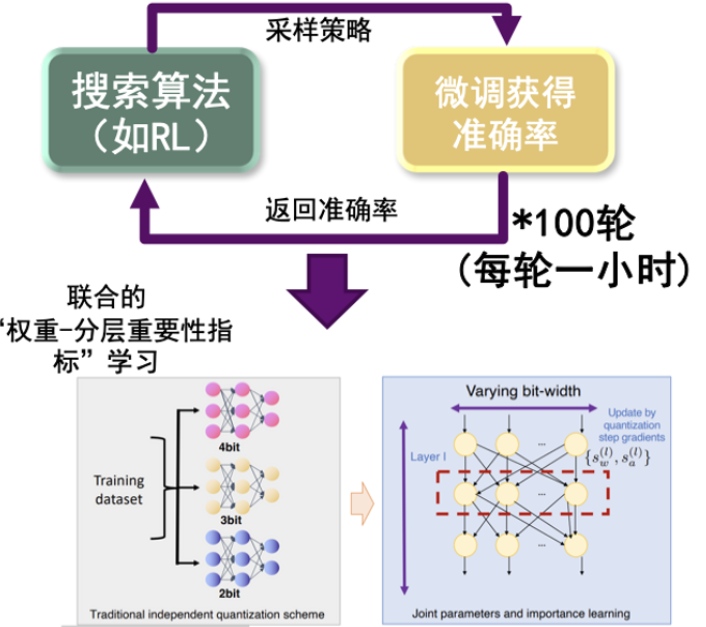
Joint Automatic Architecture Design and Low-Bit Quantization with Hardware-Software Co-Exploration
Mingzi Wang, Yuan Meng, Chen Tang, Weixiang Zhang, Yijian Qin, Yang Yao, Yingxin Li, Tongtong Feng, Xin Wang, Xun Guan, Zhi Wang, Wenwu Zhu
AAAI Conference on Artificial Intelligence (AAAI) 2025
Jointly optimizes network architecture, ultra-low mixed precision, and accelerator design; channel-level sparse quantization reduces memory, and hardware-generated networks accelerate search.
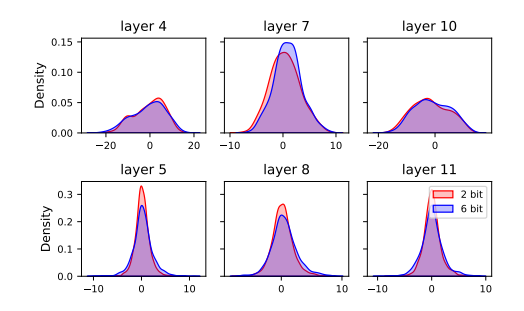
Retraining-free Model Quantization via One-Shot Weight-Coupling Learning
Chen Tang, Yuan Meng, Jiacheng Jiang, Shuzhao Xie, Rongwei Lu, Xinzhu Ma, Zhi Wang, Wenwu Zhu
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024
Analyzes bit-width interference and introduces a bit-width scheduler with alignment to improve stability; achieves strong accuracy without retraining.
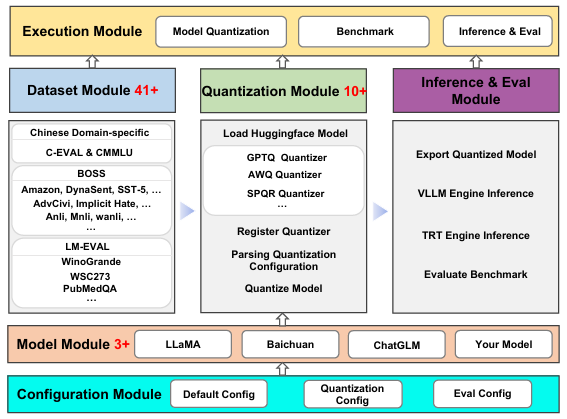
Evaluating the Generalization Ability of Quantized LLMs: Benchmark, Analysis, and Toolbox
Yijun Liu, Yuan Meng, Fang Wu, Shenhao Peng, Hang Yao, Chaoyu Guan, Chen Tang, Xinzhu Ma, Zhi Wang, Wenwu Zhu
arXiv preprint 2024
Provides a benchmark suite and toolbox to evaluate generalization of quantized LLMs across diverse datasets and calibration distributions.
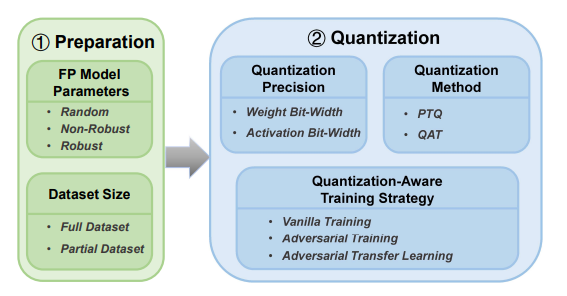
Investigating the Impact of Quantization on Adversarial Robustness
Qun Li, Yuan Meng, Chen Tang, Jiacheng Jiang, Zhi Wang
ICLR PML4LRS Workshop 2024
Defines a quantization pipeline and decomposes components to analyze their effects on adversarial robustness.
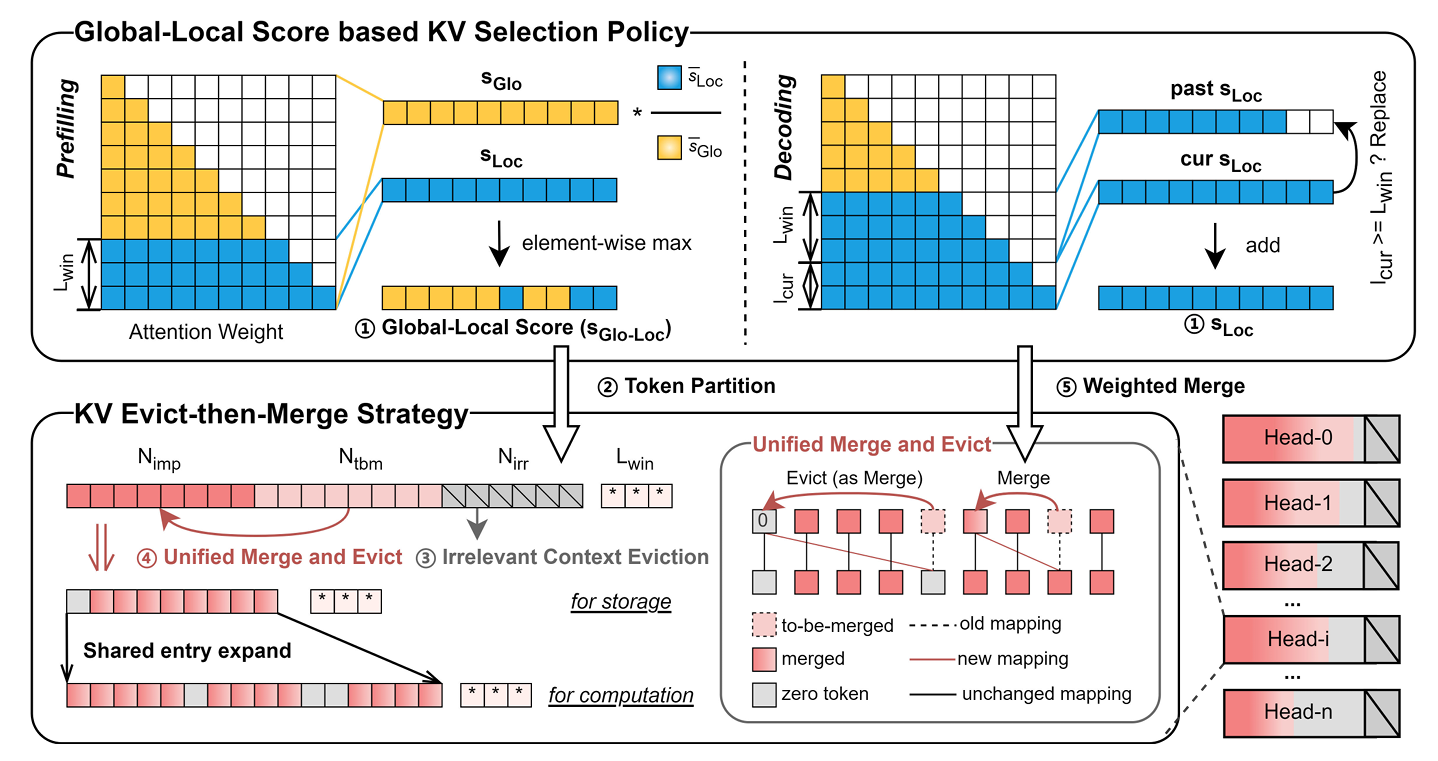
EMS: Adaptive Evict-then-Merge Strategy for Head-wise KV Cache Compression Based on Global-Local Importance
Yingxin Li, Ye Li, Yuan Meng, Xinzhu Ma, Zihan Geng, Shutao Xia, Zhi Wang
arXiv preprint 2024
Proposes EMS with a Global-Local importance score and an adaptive Evict-then-Merge framework to improve head-wise KV cache compression, achieving strong performance under extreme compression ratios.
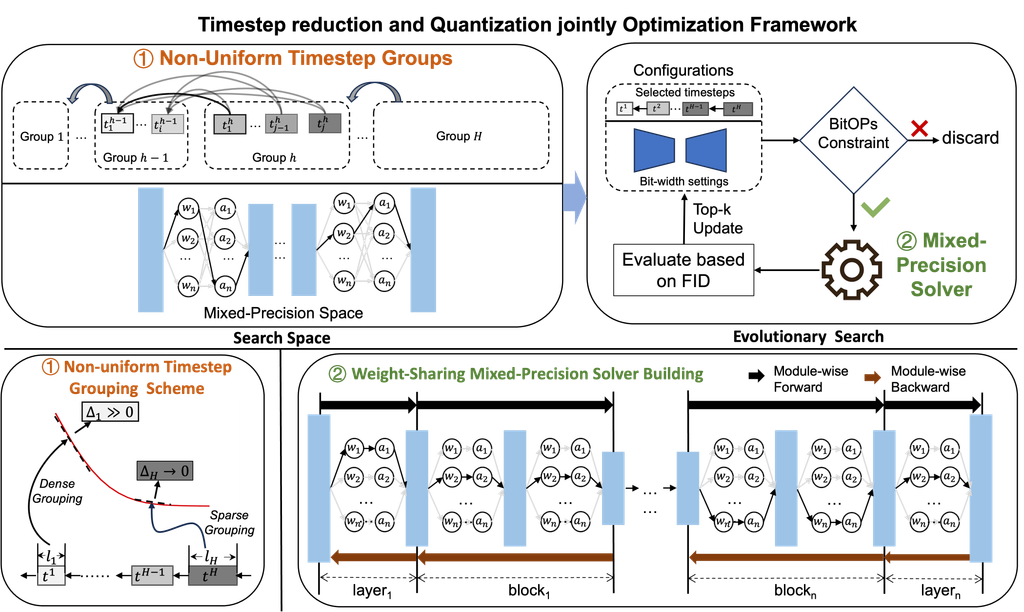
TMPQ-DM: Joint Timestep Reduction and Quantization Precision Selection for Efficient Diffusion Models
Haojun Sun, Chen Tang, Zhi Wang, Yuan Meng, Jingyan Jiang, Xinzhu Ma, Wenwu Zhu
arXiv preprint 2024
Achieves more than 10x BitOPs savings on five datasets while maintaining generation quality.
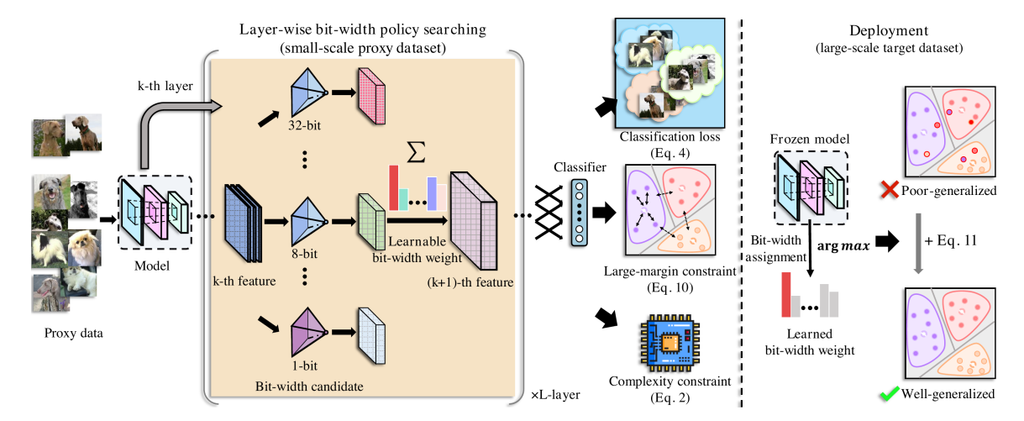
SEAM: Searching Transferable Mixed-Precision Quantization Policy through Large Margin Regularization
Chen Tang, Kai Ouyang, Zenghao Chai, Yunpeng Bai, Yuan Meng, Zhi Wang, Wenwu Zhu
ACM International Conference on Multimedia (ACM MM) 2023
Searches transferable mixed-precision policies using large-margin regularization.
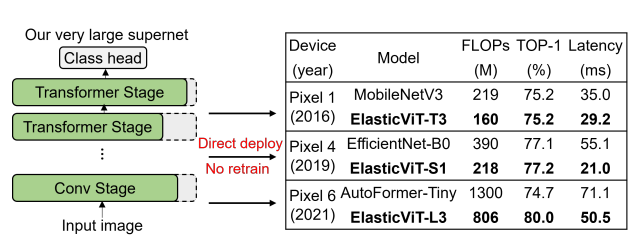
ElasticViT: Conflict-aware Supernet Training for Deploying Fast Vision Transformer on Diverse Mobile Devices
Chen Tang, Li Lyna Zhang, Huiqiang Jiang, Jiahang Xu, Ting Cao, Quanlu Zhang, Yuqing Yang, Zhi Wang, Mao Yang
IEEE/CVF International Conference on Computer Vision (ICCV) 2023
Achieves up to 2x on-device inference speed across diverse mobile devices.
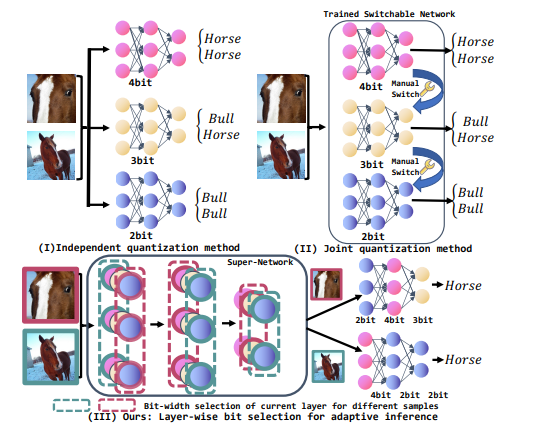
Arbitrary Bit-width Network: A Joint Layer-Wise Quantization and Adaptive Inference Approach
Chen Tang, Haoyu Zhai, Kai Ouyang, Zhi Wang, Yifei Zhu, Wenwu Zhu
ACM International Conference on Multimedia (ACM MM) 2022
Saves 10%-15% compute compared with highly compressed models.